[ADSP] 3과목 - 4장.통계분석, 기초통계분석, 회귀분석
1절. 통계분석
통계분석
통계 : 특정대상을 대상으로 수행한 조사나 실험을 통해 나온 결과에 대한 요약된 형태의 표현이다.
- 기술통계(descriptive statistic)
- 주어진 자료의 파단이나 예측같은 주관이 섞일수 있는 과정을 배재하여 통계집단의 여러 특성을 수화하여 객관적인 데이터로 나타내는 통계 분석 방법론
- 평균, 표준편차, 중위수, 최빈값, 그래프 등 구하는것
- 통계적 추론 (추측통계, inference statistics)
- 수집된 자료를 이용해 대상집단(모집단)에 대한 의사결정을 하는 것으로 sample을 통해 모집단을 추정하는것
- 모수추정, 가설점정, 예측 ★☆
표본조사 ★
대부분의 설문조사는 표본조사로 진행되고 모집단에서 샘플을 추출하여 진행하는 조사
(1) 표본 오차 SE(sampling error) : 평균들의 표준 편차
- 모집단을 대표하는 표본 단위들이 조사 대상으로 추출되지 못함으로써 발생하는 오차
(2) 비표본 오차(non-sampling error)
- 표본오차를 제외한 모든 오차. 조사과정에서 발생하는 모든 부주의, 알 수 없는 원인 등
- 조사대상이 증가하면 오차가 커진다.
- 표본값으로 모집단의 모수를 추정할 때 표본오차의 비표본오차가 발생할 수 있다.
(3) 표본편의(sampling bias) ★
- 모수를 작게 또는 크게 할 때 추정하는 것과 같이 표본추출방법에서 기인하는 오차
- 표본 편의는 확률화(randomization)에 의해 최소화하거나 없앨 수 있다. ★
√ 확률화(randomization): 모집단으로부터 편의되지 않은 표본을 추출하는 절차
√ 확률표본(random sample): 확률화 절차에 의해 추출된 표본
(4) 표본조사에서 유의해야할 점 : 응답오차, 유도질문 등 ★
2-1. 표본추출의 방법 ★★
(1) 단순 랜덤 추출법
- 각 샘플에 번호 부여 후 임의의 n개를 추출 ★
- 모집단의 각 샘플은 선택될 확률이 동일하다.
(2) 계통 추출법 ★
- 번호를 부여한 샘플을 나열
- k개씩 n개의 구간으로 나눈다
- 첫 구간에서 하나를 임의로 선택한 후 매번 k번개씩 띄어서 n개의 표본을 선택 ★
(3) 집락(군집) 추출법 (cluster random sampling)
- 모집단을 차이가 없는 여러개의 집단으로 나누고. 일부 집단을 랜덤으로 선택 후 각 집단에서 표본을 임의 선택 ★
(4) 층화 추출법 ★★ (stratified random sampling)
- 성격에 따라 서로 유사한 것끼리 몇 개의 집단 또는 층(strata)으로 나눈다. ★
- 각 집단 내에서 원하는 크기의 표본을 랜덤하게 추출
- 실험으로도 자료수집 가능 (실험 대상에 처리를 하고 결과를 관측해 자료 수집)
- 표본조사는 대상 집단의 일부 추출 → 현상 관측 또는 조사
측정
1. 질적 자료 (qualitative data)
(1) 명목척도 : 특성을 분류하거나 확인하기위해 사용, 어느 집단에 속할지 분류시 사용
예) 성별, 출생지, 혈액형 ★
(2) 서열척도(순서척도)
- 순위만 제공할뿐 비교는 할 수 없음
- 서열척도는 명목척도와 달리 숫자의 크기를 의미있게 활용가능
- 예) 선호도(Good/Medium/Bad) 등
2. 양적 자료(quantitative data) : 연속형 자료를 나타내는 척도
(1) 구간척도(등간척도)
- 순위를 부여하되 순위 사이의 간격이 동일하여 양적인 비교가 가능
- 속성의 양을 측정, 비율은 별 의미 없음. 더하기,빼기 가능 (곱하기,나누기 불가능!!)
- 절대적인 0점 존재하지 않음 ★
- 예) 온도, 물가지수 등
(2) 비율척도
- 절대적 기준인 0값 존재, 사칙연산 가능 ★
- 예) 무게, 나이, 연간소득, 직장까지 거리 등
확률
표본공간(sample space) : 어떤 실험을 실시할 때 나타날 수 잇는 모든 결과들의 집합
사건 : 관찰자가 관심이 있는 사건으로 표본공간의 부분집합
원소 : 나타날 수 있는 개별의 결과들을 의미
확률변수(random variable)
- 특정값이 나타날 가능성이 확률적으로 주어지는 변수
- 정의역(domain)이 표본공간, 치역(range)이 실수값(0<y<1)인 함수이다.
조건부 확률
- 사건B가 발생했다는 조건아래 사건A가 발생할 확률 P(A|B)=P(A∩B)/P(B) (조건 P(B) > 0)
- 독립사건 : 사건A와 사건B는 서로 무관함 P(A∩B)=P(A)*P(B), P(B|A) = P(B), P(B|A)=P(A)
- 배반사건: 교집합이 공집합(0임), P(A∩B) = 0, 그러니까 P(AUB)=P(A)+P(B)
확률분포
1. 이산형 확률 변수
- 0이 아닌 확률값을 갖는 확률 변수를 셀수 있는 경우
- 확률 크기를 표현하는 함수 = 확률 질량 함수
- 기댓값 E(X)=∑x*f(x)
| 베르누이 확률분포 ★ | - 결과가 2개만 나오는 경우 (ex. 동전 던지기, 합격/불합격) - 모수가 하나이며 반복되는 사건이 일어나는 실험의 반복적 실행을 확률분포로 나타낸것 |
| 이항분포 | 베르누이 시행을 n번 반복했을때 k번 성공할 확률 |
| 기하분포 | 성공확률이 p인 베르누이 시행에서 첫번째 성공이 있기까지 x번 실패할 확률 |
| 포하송분포 | 시간과 공간내에서 발생하는 사건의 발생횟수에 대한 확률분포 |
| 다항분포 | 이항분포를 확장한 것으로 세가지 이상의 결과를 가지는 반복 시행에서 발생하는 확률 분포 |
2. 연속형 확률 분포
- 가능한 값이 실수의 어느 특정구간 전체에 해당하는 확률변수
- 한 점에서의 확률은 0, 구간에서의 확률값 = 확률밀도함수
| 균일분포 | 모든 확률변수x가 균일한 확률을 가지는 확률분포 (다트의 확률분포) |
| 정규분포 ★ | 평균이 μ이고, 표준편차가 σ인 x의 확률밀도함수 평균이 0이고, 표준편차가 1이면 표준정규분포 |
| 지수분포 | 어떤 사건이 발생할 때까지 경과 시간에 대한 연속확률분포이다. |
| 카이제곱분포 | 모평균과 모분산이 알려지지 않은 모집단의 모분산에 대한 가설 검정 두 집단간의 동질성 검정에 사용 |
| t- 분포 ★ | 평균이 0을 중심으로 좌우 동일한 분포를 따른다. 두 집단의 평균이 동일한지 확인. 표본을 많이 뽑지 못하는 경우 사용 |
| f-분포 ★ | 두 집단간 분산의 동일성 검정에 사용 |
정규분포의 당위성
- 이항분포의 근사
- 중심극한 정리: 표본 크기가 N인 확률분포의 표본평균은 N이 충분히 크면 정규분포를 따름
- 오차의 법칙: 실제값일 가능성이 가장 높은값 MLE가 측정값의 평균이면 정규분포를 따름
중심극한정리
- 이 정리를 통해 모집단분포가 균등분포, 이항분포, 지수분포를 따르더라도 표본의 크기가 상당히 크면 모집단의 특성을 추정하는데 정규분포의 이점을 활용할 수 있음.
- 표본 개수가 30개 이상이면 모수를 몰라도 표본통계량으로 정규분포를 구성하여 모수를 추정 가능
추정과 가설검정
# 모수적 추론 : 모집단에 특정 분포를 가정하고 모수를 추론
정균분포를 이루고, 분산이 같아야함. 등간척도나 비율척도로 측정
# 비모수적 추론 : 모집단에 특정 분포 가정을 하지 않음. 분포형태에 관한 검정 실시
표본수가 적고, 명목척도, 서열척도인 경우 (성별, 혈액형)
# 모분산의 추론 ★
- 표본의 분산은 카이제곱 분포를 따른다.
- 모집단의 변동성 또는 퍼짐의 정도에 관심이 있는 경우 모분산이 추론의 대상이 된다.
- 모집단이 정규 분포를 따르지 않더라도 중심극한정리를 통해 정규모집단으로부터 모분산에
- 대한 검정을 유사하게 시행할 수 있다.
통계적 추론은 추정과 가설검정으로 나뉜다.
1. 추정
1-1. 점 추정
- '모수가 특별한 값'일것이라고 추정하는
- 가장 참값이라고 여겨지는 하나의 모수의 값을 택하는 것
- 표본의 평균, 중위수, 최빈값 등을 사용
- 적률법, 최대우도법, 최소제곱법으로 구함
1-2. 구간 추정
- 점추정의 정확성을 보완하기 위해 확률로 표현된 믿음의 정도하에서 '모수가 특정한 구간'에 있을것이라고 선언하는것
- 실제 모집단의 모수가 신뢰구간에 꼭 포함되어 있는 것은 아니다. ★
- 신뢰수준 : 모수값을 포함하는 신뢰구간이 존재할 확률 (90%, 95%, 99%)
- (신뢰수준 95% : 주어진 신뢰구간에 모수가 포함될 확률 95%라는 의미) ★
- 신뢰구간 : 일정한 크기의 신뢰수준으로 모수가 포함되리라고 기대되는 범위 ★
- 신뢰수준이 높아지면 신뢰수준의 길이는 길어진다. ★
- 표본의 수가 많아지면 신뢰구간의 길이는 짧아진다. ★
- 모집단의 확률분포를 정규분포라 가정할 때, 95% 신뢰수준 하에서 모평균 μ 의 신뢰구간
2. 가설검정
- 모집단에 귀무가설(H0)과 대립가설(H1)을 설정하고, 표본관찰을 통해 채택여부 결정
- 귀무가설이 옳다는 전제하에서 관측된 검정통계량의 값보다 더 대립가설을 지지하는 값이 나타날 확률을 구하여 귀무가설의 채택여부 결정한다.
- 독립변수의 기울기(회귀계수)가 0이라는 가정을 귀무가설, 기울기가 0이 아니라는 가정을 대립가설로 놓는다. ★★
- 즉 유의수준을 평가하여 귀무가설을 채택할지 거부할지를 판단한다.★
- 귀무가설(H0) : 대립가설과 반대의 증거를 찾기 위해 정한 가설 (관습적/보수적인 주장)
- 대립가설(H1) : 증명하고 싶은 가설 (적극적으로 우리가 입증하려는 주장), 뚜렷한 증거가 있을때 주장★
- 유의수준(알파a) : 귀무가설을 기각하게 되는 확률의 크기로 '귀무가설이 옳은데도 이를 기각하는 확률의 크기'
- 유의확률(p-value) : 대립가설이 틀릴 확률 ★
2-1. 가설검정의 오류
- 1종 오류 : 귀무가설이 사실인데도 사실이 아니라고 판정 ★ (2종 오류와 상충관계)
- 2종 오류 : 귀무가설이 사실이 아님에도 사실이라고 판정
- 기각역 : 귀무가설을 기각하는 통계량의 영역(대립가설이 맞을 때 그것을 받아들이는 확률)
- 검정력 : 대립가설이 사실일 때, 이를 사실로서 결정할 확률 1 - β(2종오류)
| 정확한 사실\가설검정 결과 | 귀무가설이 사실이라고 판정 | 귀무가설이 사실아니라고 판정 |
| 귀무가설(H0)이 사실임 | 옳은 결정 | 제 1종 오류(α) ★ |
| 귀무가설(H0)이 사실이 아님 | 제 2종 오류(β) | 옳은 결정 |
2-2. p-value (유의확률) ★
- 귀무가설을 얼마나 지지하는지 나타낸 확률. 1종오류를 범할 확률 ★
- 1종 오류시 우리가 내린 판정이 잘못되었을 실제확률 ★
- 미리 정해놓은 유의수준값보다 작을 경우 귀무가설은 기각, 대립가설은 채택 ★★
- ex) 유의수준 0.05하에서 p-value가 5.94e-10로 더 작아서 귀무가설은 기각함
- 0~1 사이의 값을 가지며, 전체 표본에서 하나의 표본이 나올 수 있는 확률
- 0.05 이상이면 회귀계수값이 유의하지 않다고 봄.
- 0.05 이하의 값이면 회귀모형이 유의하다고 봄.
2절. 기초통계분석
기술통계(Descriptive Statistics)
자료의 특성을 표, 그림, 통계량을 사용해 쉽게 파악할 수 있도록 정리/요약하는 것
최소값, 최대값, 평균, 표준편차, 분산 사용
그래프 ★
(그래프의 결과가 통계학적인 유의미를 갖는 것은 아님!)
(1) 히스토그램 ★ hist()
- 도수분포표를 이용하여 표본자료의 분포를 나타낸 연속형 그래프
- 수평축 위에 계급구간을 표시, 각 계급의 상대도수에 비례하는 넓이의 직사각형을 그린 것
- 임의로 순서를 바꿀수 없고, 막대의 간격이 없다.
- 많은 데이터를 가지고 있는 경우 보다 정확한 관계 파악을 할 수 있다. ★

(2) 막대그래프 barplot() : 명목형 변수의 빈도에 활용, 막대사이가 끊겨있는 모양
(3) 줄기-잎 그림 ★: 각 데이터의 점들을 구간단위로 요약하는 방법으로 계산량이 많지 않음
(4) 산점도 ★ plot(x,y)
- 두 특성의 값이 연속적인 수인 경 우, 2개 수치형 변수의 상관관계를 나타냄
- 각 이차원 자료에 대해 좌표가 (특성 1의 값, 특성 2의 값)인 점을 좌표평면 위에 찍은 것
(5) 파레토그림 ★
- 명목형 자료에서 ‘중요한 소수’를 찾는데 유용한 방법
(6) 상자그림 ★ boxplot()
- 이상치 판단에 적합.
- 최소값, 최대값, Q1, Q2, Q3, 중위값, IQR길이, 1사분위, 3사분위
- 최소값 : Q1 - (1.5*IQR)
- 최대값 : Q3 + (1.5*IQR)
- IQR = Q3-Q1 ★
- NA는 제거하고 그려짐
- 분포차이를 비교할 수 있지만 분포 차이의 유의미함을 보일 순 없다.

ex)

분포의 형태에 관한 측도
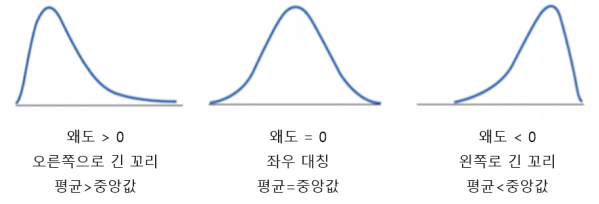
1. 왜도
- 분포의 비대칭 정도를 나타내는 측도
- 왜도 값이 0인 경우 : 평균 = 중앙값 = 최빈값 (정규분포와 유사)
- 왜도 양수 (오른쪽으로 꼬리가 긺) : 최빈값 < 중앙값 < 평균
- 왜도 음수 (왼쪽으로 꼬리가 긺) : 최빈값 > 중앙값 > 평균
2. 첨도
- 분포의 중심에서 뾰족한 정도
- 값이 3에 가까울 수록 정규분포 모양 가짐
- 정규분포의 첨도를 0으로 나타내기 위해 첨도값에서 3을 빼서 사용하기도 함

t-검정
모집단의 분산이나 표준편차를 알지못할 때
모집단을 대표하는 표본으로부터 추정된 분산이나 표준편차를 가지고 검정하는 방법
- 평균값이 올바른지, 두집단의 평균 차이가 있는지를 검증하는 방법 : 모수검정, 비모수검정
4-1. 모수 검정
- 표본이 정규성을 갖는다는 모수적특성을 이용하는 통계방법
- 검정 실시 : 관측된 자료를 이용해 표본평균, 표본분산 등을 구하여 이용
- 표본 정규성 반드시 확보되어야 함.
- 등간척도, 비율 척도
- 평균
- 피어슨 상관계수
- one sample t-test, two sample t-test, paired t-test, one way anova
4-2. 비모수 검정
- 정규성 검정에서 정규분포를 따르지 않는다고 증명되거나 표본 군집당 10명 미만의 소규모 실험에서와 같이 정규분포임을 가정할 수 없는 경우에 사용
- 모집단의 분포에 아무 제약을 가하지 않고 검정을 실시하는 검정 방법★
- 모집단에 대한 아무런 정보가 없을 때 사용하는 방법★
- 관측 자료가 특정분포를 따른다고 가정할 수 없는 경우에 이용 ★
- 평균과 분산이 없으므로 평균 값의 차이, 신뢰구간을 구할 수 없다. ★
- 절대적인 크기에 의존하지 않는 관측 값의 순위나 부호 등을 이용★
- 모집단 특성을 몇개의 모수로 결정하기 어렵고 많은 모수가 필요할수있다.★
- 명목척도, 서열척도
- 중앙값
- 스피어만 상관계수
| 피어슨 상관계수 (-1 ~ 1) |
- 두 변수간의 선형적인 크기만 측정 가능, 비선형적인 관계는 나타내지 못한다.★ - 연속형 변수만 가능, 정규성을 가정 - 대상이 되는 자료의 종류 : 등간척도, 비율척도 ★★ - x,y의 공분산을 표준편차의 곱으로 나눈값 예) 국어 점수와 영어점수의 상관계수 |
| 스피어만 상관계수 ★ (-1 ~ 1) |
- 두 변수 간의 비선형적인 관계도 나타낼 수 있음 ★★ - 연속형 외에 이산형 순서형도 가능 ★ - 관계가 랜덤이거나 존재하지 않을 경우 상관계수 모두 0에 가깝다. ★ - 원시 데이터가 아니라 각 변수에 대해 순위를 매긴 값(서열)을 기반으로 한다. ★ - 비모수적이다. - 대상이 되는 자료의 종류 : 순서척도, 서열척도 ★★ (다 ㅅ으로 시작!) - 0은 상관 관계가 없음을 의미한다. 예) 국어성적 석차와 영어성적 석차의 상관계수 |
# 부호 검정(Sign test) ★
- 비모수 검정 방법
- 표본들이 서로 관련되어 있는 경우 짝지어진 두 개의 관찰치들의 크고 작음을 표시하여 그 개수를 가지고 두 분포의 차이가 있는지에 대한 가설을 검증하는 방법
- 이 표본에 의한 분산비 검정은 두 표본의 분산이 동일한지를 비교하는 검정으로 검정통계량은 F분포를 따른다.
# 정규성 검정 ★
(1) Q-Q plot ★ (그래프 그려서 시각적으로 확인하는 방법)
(2) Shapiro-Wilk test ★ (p-value가 0.05보다 크면 정규성 가정)
(3) Kolmogorov-Smirnov test (p-value가 0.05보다 크면 정규성 가정)
(4) 히스토그램
R
| head(data명) | 데이터를 기본 6줄 보여줌 |
| head(data명, n) | n번째 라인까지 보여줌 |
| summary(data명) | 데이터의 전반적인 기초통계량 |
| mean(data명$column명) | 컬럼의 평균 |
| median(data명$column명) | 컬럼의 중앙값 |
| sd(data명$column명) | 컬럼의 표준편차 = sqrt(var()) = var()^(1/2) (stdev아님!!) |
| var(data명$column명) | 컬럼의 분산 |
| quantile(data명$column명) | 컬럼의 분위수 |
인과관계
- 반응변수(종속변수) : 영향을 받는 변수, 보통 y로 표기 ex)아파트가격
- 설명변수(독립변수) : 영향을 주는 변수, 보통 x, x1, x2으로 표기 ex)방개수,면적,거리 등
- 공분산 : 두 확률변수 X, Y의 상관정도를 나타내는 값
- 공분산의 부호만으로 두 변수간의 방향성 확인 가능
- 공분산이 음수면 X가 증가할 때 Y는 감소
- X, Y가 서로 독립이면 cov(X,Y)=0 이다.
- 상관분석(Correlation Analysis)
- 두 변수의 상관관계를 알아보기 위해 상관계수를 사용
- 상관계수 : 공분산의 문제를 해결한 값, -1과 1사이
정규화(Regularization)
- 베타값에 제약(penalty)을 주어 모델에 변화를 주는 것
- 값이 클수록 제약이 많아져, 적은 변수가 사용되고, 해석이 쉬워지지만 underfitting됨
- 값이 작아질수록 제약이 적어, 많은 변수가 사용되고, 해석이 어려워지며 overfitting됨
| 구분 | 릿지(Ridge) | 라쏘(Lasso) ★ | 엘라스틱넷(Elastic Net) |
| 제약식 | L2 norm ★ | L1 norm ★ | L1 + L 2norm |
| 변수선택 | 불가능 | 가능 | 가능 |
| 장점 | 변수 간 상관관계가 높아도 좋은 성능 |
변수 간 상관관계가 높으면 성능이 떨어짐 |
변수 간 상관관계를 반영한 정규화 |
7-1. 라쏘(Lasso) 회귀분석 ★
- 회귀분석에서 사용하는 최소제곱법에 제약조건(L1 norm)을 부여하는 방법이다.
- 회귀계수의 절대값이 클수록 패널티를 부여한다. ★
- 자동적으로 변수선택 ★
- lambda값으로 penalty의 정도를 조정한다. ★
- MSE(평균제곱오차)와 Penalty항의 합이 최소가 되게 하는 파라메터를 찾는 것이 목적
7-2. 라쏘(Lasso) 장점
- 제약 조건을 통해 일반화된 모형을 찾는다.
- 가중치들이 0이 되게함으로써 그에 해당하는 불필요한 특성들을 제외해준다,
- 모델에서 가장 중요한 특성이 무엇인지 알게 되는 등 모델 해석력이 좋아진다.
7-3. 릿지(Ridge) 회귀분석 (R이니까 2!)
- 가중치들은 0에 가까워질뿐 0이 되지는 않는다.
- 변수선택 불가능, 변수간 상관관계가 높아도 좋은 성능
7-4. 데이터 스케일링(scaling)
- 정규화 : 값의 범위를 [0,1]로 변환하는 것, min-max nomalization
= X-Xmin / Xmax-Xmin
ex) 0,100인 경우 50점? 50-0/100-0 = 0.5
- 표준화 : 특성의 값이 정규분포를 갖도록 변환, 평균0, 표준편차1
= X-평균/표준편차
3절. 회귀분석
회귀분석
: 종속변수에 미치는 영향력의 크기를 파악하여 독립변수의 특정한 값에 대응하는 종속변수값을 예측하는 선형모형을 산출하는 방법이다.
or 하나 이상의 변수들이 다른 변수에 미치는 영향에 대해 추론하기위한 통계적 분석방법
- 반응변수(종속변수) : 영향을 받는 변수, 보통 y로 표기 ex) 아파트가격
- 설명변수(독립변수) : 영향을 주는 변수, 보통 x, x1, x2으로 표기 ex) 방개수,면적,거리 등
- 회귀계수 : 독립변수에 영향을 줌(w), 회귀계수에 따라 선형,비선형 회귀로 나뉨
- 회귀계수 추정 : 최소자승법(최소제곱법) ★
- 최소자승법 : 데이터와 추정된 함수가 얼마나 잘 맞는지 잔차들의 제곱(square)합 구해서 그것을 최소로 하는 값을 구하여 측정결과를 처리하는 방법
회귀모형에 대한 가정 ★
- 선형성 : 독립변수의 변화에 따라 종속변수도 변화하는 선형인 모형 ★
- 독립성 : 잔차와 독립변수의 값이 관련되어 있지 않음 ★
- 정상성(정규성) : 잔차항이 정규분포를 이뤄야 함 ★
- 등분산성 : 오차항들의 분포는 동일한 분산을 가짐 (산점도가 나팔모양이면 안됨)
- 비상관성 : 잔차들끼리 상관이 없어야 함
- (이분산성 아님!!)

회귀분석 모형에서 확인할 사항 ★★
(1) 모형이 통계적으로 유의미한가? ⇒ F통계량(p값) 확인
F 통계량 확인, F통계량의 p-값이 0.05 보다 작으면 추정된 회귀식은 통계적으로 유의미하다고 한다.
(2) 회귀계수들이 유의미한가? ⇒ 회귀계수의 T값과 유의확률 (p-value) 또는 신뢰구간 확인
(3) 모형이 얼마나 설명력을 갖는가? ⇒ 결정계수(R-square)를 확인
결정계수를 확인, 결정계수는 0에서 1값을 가짐, 높은 값을 가질수록 추정된 회귀식의 설명력이 높다.
(4) 모형이 데이터를 잘 적합하고 있는가? ⇒ 잔차통계량, 잔차그래프를 확인하고 회귀진단
단순선형회귀분석
하나의 독립변수가 종속변수에 미치는 영향을 추정할 수 잇는 통계기법
최소제곱법, 최소자승법 ★
1) 최소제곱법, 최소자승법
자료를 가장 잘 설명하는 회귀계수의 추정치는 보통 제곱오차를 최소로 하는 값을 구하며, 이 회귀계수 추정량을 최소제곱이라고 한다.
- 데이터와 추정된 함수가 얼마나 잘 맞는지는 잔차들을 제곱(square)해서 합하고(잔차제곱합RSS,SSE), 그것을 최소로 하는 값을 구하여 측정결과를 처리하는 방법
- 잔차제곱이 가장 작은 선을 구하는 것
- 즉, 최소제곱법은 해당식이 제곱형태이니 미분해서 0이 되는 지점을 찾기 위해 잔차제곱합을 최소화하는 계수를 구하는 방법이다.

| 구분 | 일반선형 회귀분석 | 로지스틱 회귀분석 |
| 종속변수 | 연속형 변수 | 이산형 변수 |
| 모형 탐색 방법 | 1최소자승법 ★ | 최대우도법, 가중최소자승법 |
| 모형 검정 | F 검정, t 검정 | 카이제곱 검정 ★ |
2) 최대우도법
- 관측 값이 가정된 모집단에서 하나의 표본으로 추출된 가능성이 가장 크게 되도록 하는 회귀계수 추정방법
- 표본의 수가 클 경우에 최대우도법은 안정적이다.
3) 카이제곱 검정 ★
- 범주별로 관측빈도와 기대빈도의 차이를 통해서 확률모형이 데이터를 얼마나 잘 설명하는지검정하는 통계적 방법
- 독립변수와 종속변수가 모두 명목척도일 경우 적합한 통계 기법
- 일원 카이제곱검정: 적합성 검정 - 모집단이 특정한 분포를 따른다는 가설에 대해 검정
- 이원 카이제곱검정: 독립성 검정 - 표본 추출시 두 이산형 변량에 대한 독립성 여부 조사
- 동질성 검정 - 두집단 이상에 각 범주간의 비율이 서로 동일한지 검정
- - x^2분포는 t분포와 정규분포와는 달리 좌우대칭이 아니며 오른쪽으로 긴 꼬리를 갖는다.
- - 확률변수 x^2은 제곱합의 합으로 구하기 때문에 음수는 가질 수 없고 다만 가장 왼쪽에서는 0의 값을 갖는다.
회귀모형 결과 해석
- 유의성 검정 : 선형관계 성립여부. 기울기계수=0일 때 귀무가설, 0아니면 대립가설로 설정
(1) F-통계량 = 회귀제곱평균(MSR)/잔차제곱평균(MSE)
- p-value< 0.05 이면 추정된 회귀식은 통계적으로 유의하다고 결론
- F-통계량이 크면 p-value< 0.05이고 귀무가설을 기각. 모형이 유의하다고 결론
(2) t값 = Estimate(회귀계수)/Std.Error(표준오차)
(3) 결정계수 R² : 회귀식의 적합도를 재는 척도 = SSR/SST
- 총 변동 중 회귀모형에 의해 설명되는 변동이 차지하는 비율이다. ★
- 회귀모형에서 입력변수가 증가하면 결정계수도 증가한다.
- 수정된 결정계수는 유의하지 않은 독립변수들이 회귀식에 포함되었을 때 값이 감소한다. ★
- 다중회귀분석에서는 최적모형의 선정기준으로 수정된 결정계수 값을 사용하는 것이 적절★
- 총 제곱합(SST) = 회귀제곱합(SSR) + 오차제곱합(SSE)
- R² = 회귀제곱합(SSE) / 총제곱합(SST) ★ = 1-(SSR/SST)
- 결정계수가 클수록 회귀방정식과 상관계수의 설명력이 높아진다.★
다중선형회귀분석
독립변수가 k개이며 종속변수와의 관계가 선형이다.
- 다중공선성(multicollinearity)
- 다중회귀분석에서 설명변수들 사이에 선형관계가 존재하면 회귀계수의 정확한 추정이 곤란하다.
- 독립변수가 많아지면 모델 설명력이 증가하지만 모형이 복잡해지고 다중공선성 문제가 발생
- 모형의 일부 설명변수가 다른 설명변수와 상관되어 있을 때 발생하는 조건
- 중대한 다중공선성은 회귀계수의 분산을 증가시켜 불안정하고 해석하기 어렵게 만들기 때문에 문제가 된다.
- VIF함수로 값을 구할 수 있고, 보통 VIF값이 10이 넘으면 다중공선성이 존재한다고 본다.
- 해결방안: 높은 상관 관계가 있는 설명(=예측)변수를 모형에서 제거. 단계적 회귀분석 제거
최적회귀방정식의 선택 ( 설명변수의 선택)
- 모든 가능한 조합의 회귀분석 ★
- 모든 가능한 독립변수들의 조합에 대한 회귀모형을 고려해 가장 적합한 회귀모형을 선택
- AIC나 BIC의 값이 가장 작은 모형을 선택하는 방법
- 전진선택법 (Forward Selection)
- 상수모형으로부터 시작해 중요하다고 생각되는 설명변수부터 차례로 모형에 추가
- 후보가 되는 설명변수 중 가장 설명을 잘하는 변수가 유의하지 않을 때의 모형을 선택
- 설명변수를 추가했을 때 제곱합의 기준으로 가장 설명을 잘하는 변수를 고려하여 그 변수가 유의하면 추가한다. ★☆
- 후진제거법 (Backward Elimination) ★★★
- 독립변수 후보 모두를 포함한 모형에서 출발해 가장 적은 영향을 주는 변수부터 제거★
- 더 이상 유의하지 않은 변수가 없을 때의 모형을 선택
- 단계별방법 (Stepwise Selection)
- 기존의 모형에 예측변수 추가, 제거를 반복하여 최적의 모형을 찾는 방법 ★☆
- 전진선택법에 의해 변수를 추가하면서 새롭게 추가된 변수에 기인해 기존 변수가 그 중요도가 약해지면 해당변수 제거 하는 등 단계별로 추가 or 제거되는 변수의 여부 검토
- 더 이상 추가 또는 제거되는 변수가 없을 때의 모형을 선택
- 적은 수의 설명변수
- 가능한 범위 내 적은 수의 설명변수를 포함시킨다. ★☆
- lm : 회귀분석
- scope : 분석시 고려할 변수의 범위 / 가장 낮은 단계 lower에 1 입력시 상수항 의미, 가장 높은 단계 설정하기 위해서는 설명변수들 모두 써줘야 한다.
- direction : 변수 선택방법, 선택 가능 옵션은 forward(전진선택법), backward(후진선택법), both(단계적방법)