JOIN 합치기
df.join (붙이는df, how=, lsuffix='', rsuffix='')
- 가로로 합치기 (원래 데이터 오른쪽으로 새로운 데이터 붙임)
- 2개 이상의 DF 합치기 가능, 기본방식은 left outer
✔️ how (on: 어느 컬럼을 기반으로 merge 할것인지 결정)
| left | 좌측df(기존df)에 존재하는 인덱스를 기준으로해서 데이터를 합친다 |
| right | 우측(붙이는df)에 존재하는 인덱스만 가져와서 붙이기 |
| outer | 한쪽에라도 존재하는 인덱스는 다 가져와서 붙이기 (합집합) |
| inner | 양쪽 df에 공통적으로 존재하는 인덱스만 가져와서 붙이기 (교집합) |
✔️ 예제
df1 = pd.DataFrame(np.arange(4).reshape(4,1), columns=['df1'])
df2 = pd.DataFrame(np.arange(4).reshape(4,1)*100, index=[1,3,4,5], columns=['df2'])
# left는 좌측df(기존df)에 존재하는 인덱스를 기준으로해서 데이터를 합친다
dleft=df1.join(df2,how='left') # 1,3만 겹치니까 df2에 0,2인덱스는 NaN값으로 나옴
dleft
# right는 우측(붙이는df)에 존재하는 인덱스만 가져와서 붙이기
dright=df1.join(df2,how='right') #마찬가지로 1,3만 겹치니까 df1에 없는 4,5인덱스의 values는 NaN값으로 나옴
dright
# inner는 양쪽 df에 존재하는 인덱스만 가져와서 붙이기 (교집합)
dinner=df1.join(df2,how='inner')
dinner
# outer는 한쪽에라도 존재하는 인덱스는 다 가져와서 붙이기 (합집합)
douter=df1.join(df2,how='outer')
douter
# 중복컬럼이 있으면 join시 중복 방지를 위해 suffix 를 추가
ddf=df1.join(df2,how='outer',lsuffix='1') #lshuffix는 shuffix앞에 left 붙인거임
ddf
ddf=df1.join(df2,how='left',on='사과',lsuffix='1')
ddf
MERGE 합치기
df.merge (붙이는df)
- 2개의 DF만 합칠수있음, 기본적으로 inner join이다
✔️ 예제
# DataFrame 만들기
d={'사과':[1,2,3,4,5],'판매월':['1월','2월','3월','4월','5월'],'판매금액':[1000,1100,1050,950,1000]}
df1=pd.DataFrame(d,index=np.arange(5))
d={'바나나':[10,20,30,40,50],'판매월':['2월','3월','4월','5월','6월'],'금액':[1000,1100,1050,950,1000]}
df2=pd.DataFrame(d,index=[1,2,3,4,5])

# 기본 merge는 동일 이름의 커럼이 있으면 해당 컬럼 기반으로 inner join함
# 겹치는 '판매월'중에 겹치는 2,3,4,5월만 출력
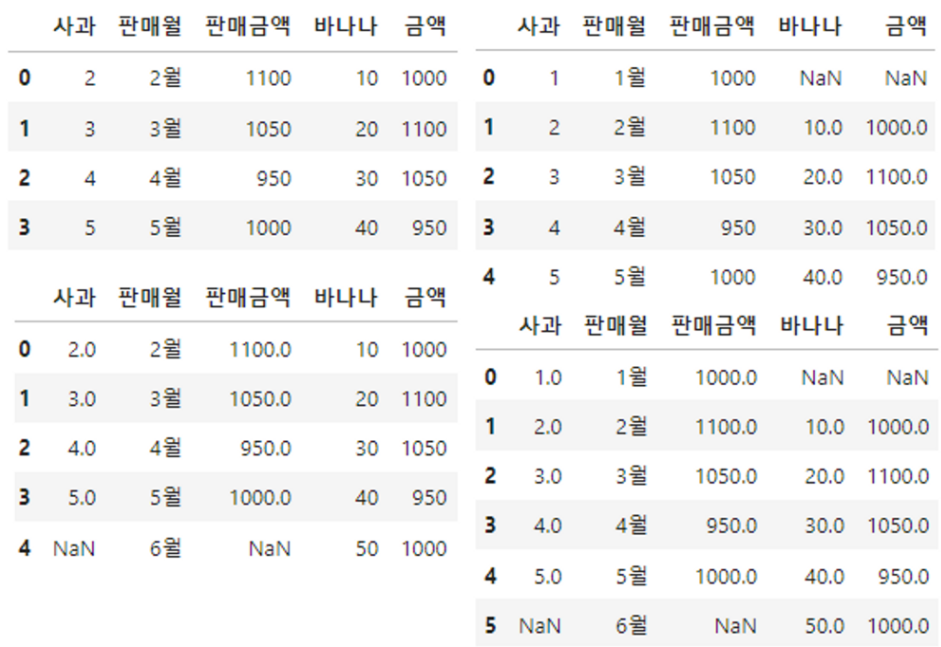
fdf=df1.merge(df2) # inner join이랑 출력되는것 같음
fdf
# 기본 merge 다른 방식으로
fdf2 = pd.merge(df1, df2)
fdf2
# left 사과기준으로 join
fdf_left=df1.merge(df2,how='left')
fdf_left
# right 바나나기준으로 join
fdf_right=df1.merge(df2,how='right')
fdf_right
# outer는 합집합
fdf_outer=df1.merge(df2,how='outer')
fdf_outer
CONCAT 합치기
- 행기준으로 합치기 (기존데이터 아래로 새로운 데이터를 붙임, 컬럼은 옆으로)
- 주로 동일 컬럼이 있음을 가정
- ignore_index : 인덱스를 재지정하는가
- pd.concat([df1,df2],ignore_index=True)
✔️ 예제
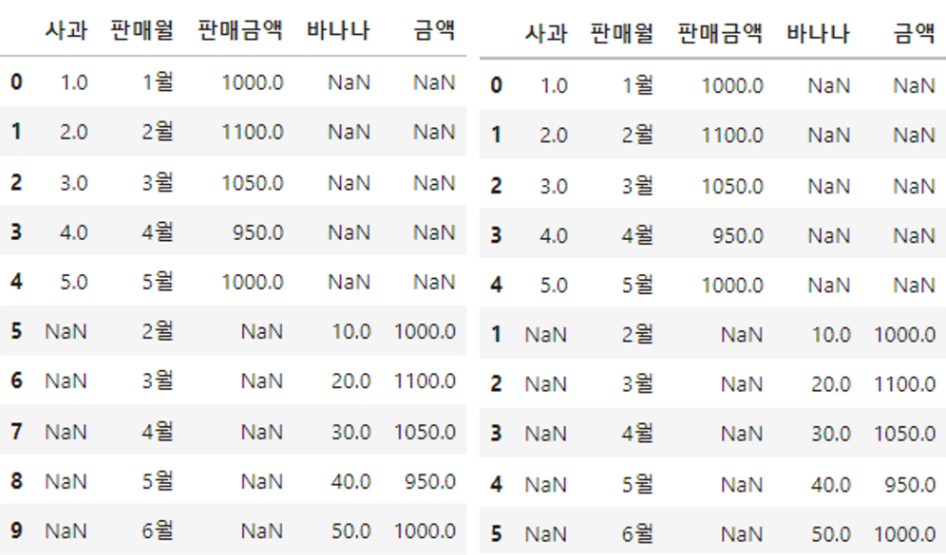
pd.concat([df1,df2],ignore_index=True)
pd.concat([df1,df2],ignore_index=False)
# 사과의 0,1,2,3,4인덱스 그대로 가져오고 아래로 바나나의 1,2,3,4,5인덱스 가져와서 붙임
'🛠️Skill > Python' 카테고리의 다른 글
| [Python] 숫자인지 문자인지 확인하기 isdigit / isalpha (0) | 2022.11.02 |
|---|---|
| [Python] 정렬하는 방법 sort 와 reverse 이해하기 (0) | 2022.10.27 |
| [Python] 클래스(class) / 인스턴스, 객체, self, super 이해하기 (0) | 2022.10.05 |
| [Python] Function/가변인자, 지역변수, 전역변수, 사용자 입력 함수 input (0) | 2022.10.03 |
| [Python] 브로드캐스팅, 슬라이싱(slicing), 인덱싱(indexing) (0) | 2022.10.03 |




댓글